
Combining different modalities as done with PET/CT, clinical decision making is shown to improve as multimodal imaging provides more information than single modality imaging. However, collecting sufficient high quality paired data from different modalities in order to train a deep learning algorithm can be challenging. In cases of data scarcity, the problem can be circumvented by applying data augmentation strategies, but when data is incomplete or series are missing, the problem is not be easily tackled. Cross-modality synthesis represents nowadays a promising application in medical image processing to manage the problem of paired data scarcity.

The Generative Adversarial Network (GAN)
Generative adversarial networks (GANs) comprises a series of unsupervised deep learning models which have achieved great results in the computer vision and medical image processing area thanks to their capability of extracting the data underlying distribution and their internal structure. They represent nowadays one of the most promising techniques to tackle the problem of data generation and augmentation. The underlying idea in GAN frameworks is to use two distinct convolutional neural networks (CNNs) trained in a zero-sum game: the first CNN aims at generating images to be as similar as possible to the target ones, while the second one aims at distinguishing between the real and the generated data.
For cross domain data synthesis, two GAN-based strategies received extensive coverage: the pix-to-pix based solutions used when data are generally paired (i.e. a co-registration between the cases of two separate domains is feasible and a good spatial correspondence between structures can be achieved) and the CycleGAN models used when data are unpaired.
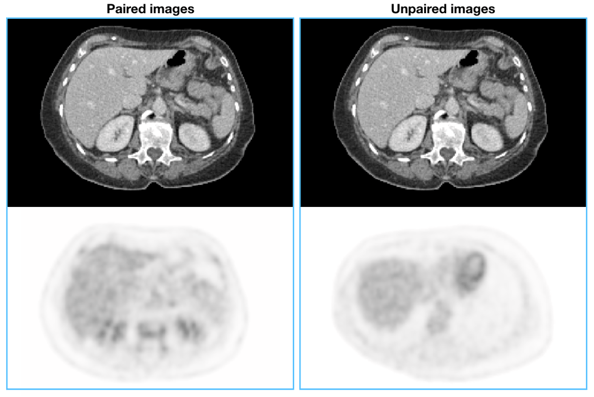
Figure 1: Example of paired and unpaired data (CT) passed to the model.
The CycleGAN represents an unsupervised technique to perform image-to-image translation across two different image domains by using collections of unpaired data (see Figure 1). Considering X and Y as two different domains (e.g. CT and PET), the model aims to find two transfer functions that allow to pass from a space to another according to GY: X → Y and GX: Y → X. The transfer functions GX and GY are produced using two CNNs, adversarially trained with two discriminator networks (DX , DY ) which respectively assess whether the passed images are real or artificially generated.
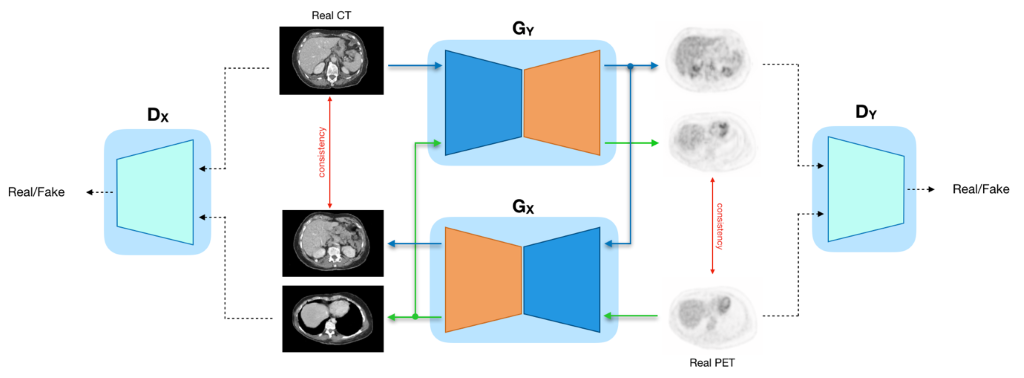
Figure 2: CycleGAN model scheme.
To the baseline model we included two additional contributes of penalty and regularization in the model loss function (denoted with the tag PR) to force the generators (GX and GY) to produce more realistic synthesized images.
EPICURE Dataset
The data used in this work are collected in the context of the EPICURE project, a study which aims to improve the understanding of diseases and the prediction of response to therapy. It mainly focuses on patients with metastatic breast cancer, especially women with histologically confirmed breast cancer, characterized by metastases that can be biopsied and that were not subjected to other malignancy treated within five years. For this study we used 18 patients who underwent both CT and PET acquisitions. The CT full body volumes are acquired with an average tube voltage equals to 100 kVp, a tube current of 221 mA and come with spacing of 0.9×0.9 ×2 mm3, resulting in 512×512 2D axial slices. The PET images are produced through the injection of 18-FDG radioactive tracer and are acquired with a resolution of 4.073×4.073×2.027 mm3, bringing to a 200×200 pixel in plane field of view. The PET intensity values are then normalized using the standardized uptake value (SUV) expression:
SUV= rw ∙a'
where r is the radioactivity concentration measured by the PET scan [kBq/ml], a’ represents the decay-corrected amount of injected radiolabeled FDG [kBq] and w is the patient weight [g].
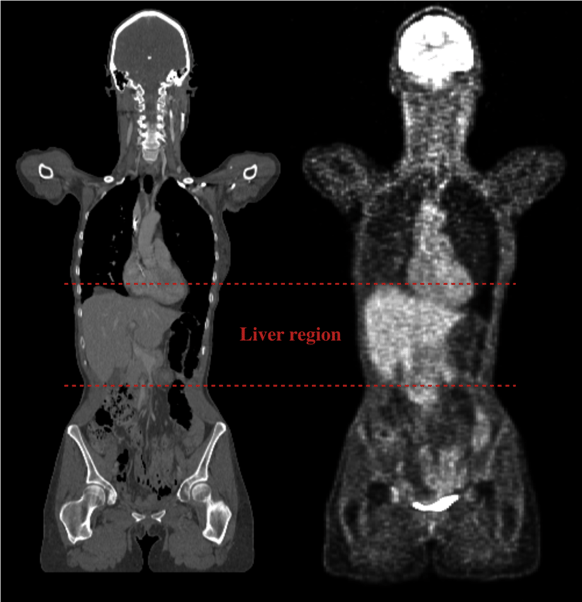
Figure. 3. Example of paired PET/CT acquisition data. In red the dashed lines limiting the liver region.
Results
The results obtained show that adding the constraints term on the generator and the regularization on discriminators improves the model’s performance to synthesize compared to the baseline models, as shown in Figure 4. Using regularization on both discriminators further stabilizes the training process, avoiding a rapid fall of the discriminator loss to zero. It also forces the generators to create more realistic images, with sharper borders, especially when creating CT images. Using only baseline models the presence of grid-like artifact were constantly present over the generated CT slices.
No significant differences in terms of quality reconstruction were observed in the results derived from training the CycleGAN model with paired or unpaired. This proves the high capability of the CycleGAN to perform cross-domain image synthesis using data where a co-registration between the cases of two separate domains is not feasible and a good spatial correspondence between structures cannot be achieved.
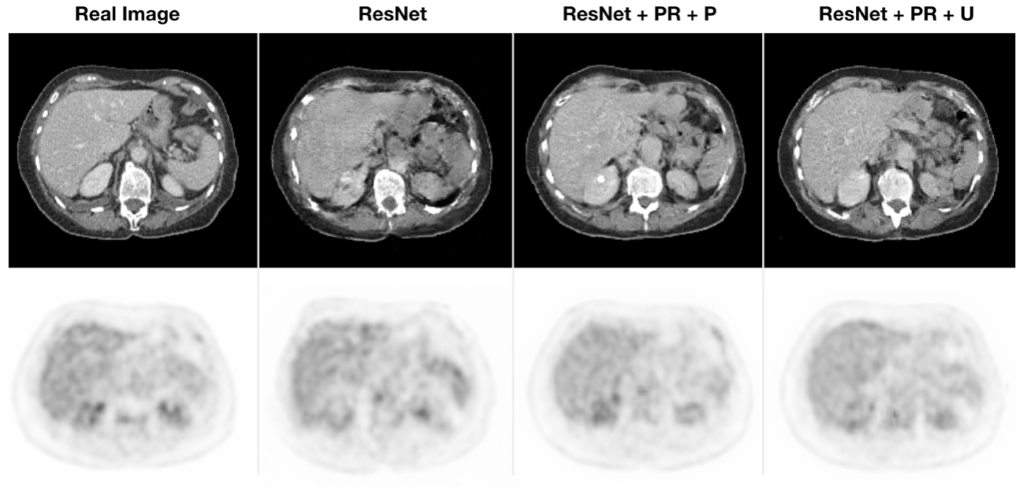
Figure. 4. Comparison between the real images and the artificial ones, created with a baseline model, and a model with penalty and regularization terms (PR) trained with paired (P) or unpaired (U) data. For simplicity we reported the images produced by using only the ResNet architecture since it performed better than the UNet.

